
Why blockchain needs indexers — the sort/filter problem
The EVM has no query engine. No sorting, filtering, or aggregation. Why fetching everything to sort in JS doesn't scale — and how indexers pre-process events.
I want you to imagine a simple feature request.
"Show me the top 10 candidates ordered by vote count."
In a PostgreSQL database:
Done. 5 milliseconds. Zero drama.
Now try the same thing in Solidity.
"...what's the Solidity equivalent of ORDER BY?"
There isn't one. The EVM has no query engine. No sorting. No filtering. No pagination. No SELECT *. No aggregation functions.
The blockchain is a state machine with a key-value store. It can tell you the vote count for candidate ID 3. It cannot tell you which candidate has the highest vote count without you fetching every candidate and sorting them yourself.
1. The Story: The "Top Candidates" Feature
A product manager (me, in a self-imposed PM hat) asked for a leaderboard: the top 5 candidates by votes, ranked in real-time.
My first attempt:
With 5 candidates: 5 RPC calls, sort, done. Fast enough. With 100 candidates: 100 RPC calls. Slow but functional. With 1,000 candidates: 1,000 RPC calls. Rate-limited, times out.
The sort logic is correct. The problem is that to sort, you must fetch everything first. And fetching everything at scale hits the RPC limits we discovered in Module M2.2.
2. Why the EVM Cannot Sort
The EVM's storage model is a simple mapping:
Mappings are hash-addressed:
To find the mapping value for key 3 (candidate ID 3), you compute the hash and look up that slot. This is O(1).
But to find all keys that satisfy some condition (vote count > 100) — there is no index. You cannot query the mapping. You can only look up individual known keys.
This is the fundamental architectural constraint:
3. The Visual: What an Indexer Does
[!TIP] VISUAL TRIGGER FOR FRONTEND: Animate the EVM storage as a flat, unsorted key-value grid — show a sort query bouncing off it. Then show the indexer as a processing pipeline that ingests events and writes them into a structured, indexed database with a GraphQL query interface on top.
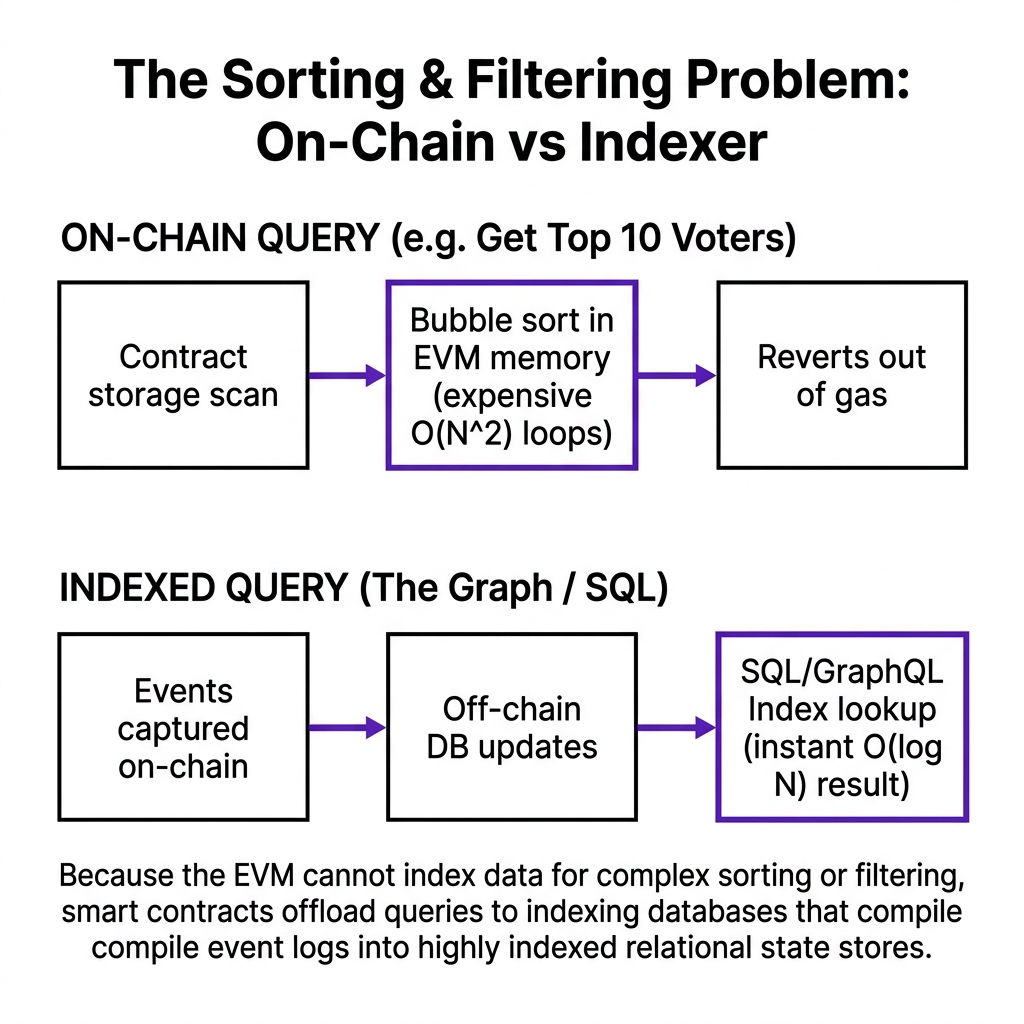
4. The ProofChain Example
ProofChain is a proof-of-existence system. When you register a document, it emits:
Without an indexer, to answer "show me all documents registered by 0x71C..." you'd need to fetch all ProofRegistered events and filter by owner — potentially millions of events.
With an indexer (The Graph), your subgraph handler processes each ProofRegistered event and stores it in a Proof entity table with indexed fields. Your frontend queries:
Result: instant, sorted, filtered — served from a PostgreSQL-backed subgraph. No RPC calls. No pagination loops.
The indexer is not "cheating" at decentralization. The source of truth is still the blockchain. If the indexer goes down or returns incorrect data, anyone can verify the true state by replaying events directly from the chain. The Graph's hosted service provides economic incentives (GRT token) for indexers to remain honest and available. This is decentralized infrastructure at the data layer.
The "I'll Add The Graph Later" Trap:
Developers often build with direct contract reads during development (where scale isn't a problem) and plan to add The Graph "later in production." This creates a forced architecture migration at the worst time — when users are waiting. The correct pattern is to design your contract events with indexing in mind from day one: emit all data the UI needs in events, and mark frequently-queried parameters as indexed.
Look at ChainElect's MyContract.sol. Find the Voted event definition. Which parameters are indexed? Now think about the leaderboard feature: to build a sorted leaderboard, what data would your subgraph handler need to store when processing each Voted event? What entity structure (fields, types) would enable an efficient ORDER BY voteCount DESC query?
Was this lesson helpful?
Let us know what you think of this specification. (submitting anonymously)