
How The Graph works internally
Subgraphs, indexing nodes, AssemblyScript handlers, and how The Graph processes every blockchain event into a queryable GraphQL database.
When I first heard "The Graph indexes your contract events," I nodded confidently without understanding what that actually meant.
Indexes? Like a database index? Like a book index? What does indexing mean here?
This lesson is the one I wish I'd had before I tried to write my first subgraph.
1. The Layered Architecture
The Graph is a decentralized indexing protocol — a network of nodes that run indexing jobs (called subgraphs) and expose the results as GraphQL APIs.
[!TIP] VISUAL TRIGGER FOR FRONTEND: Animate this as three animated layers. Layer 1: blockchain emitting events (pulsing). Layer 2: The Graph indexer consuming them (shows handler function running). Layer 3: PostgreSQL building up rows in real-time. Layer 4: GraphQL cursor querying the result table. Show the entire pipeline processing a single "Voted" event end-to-end.
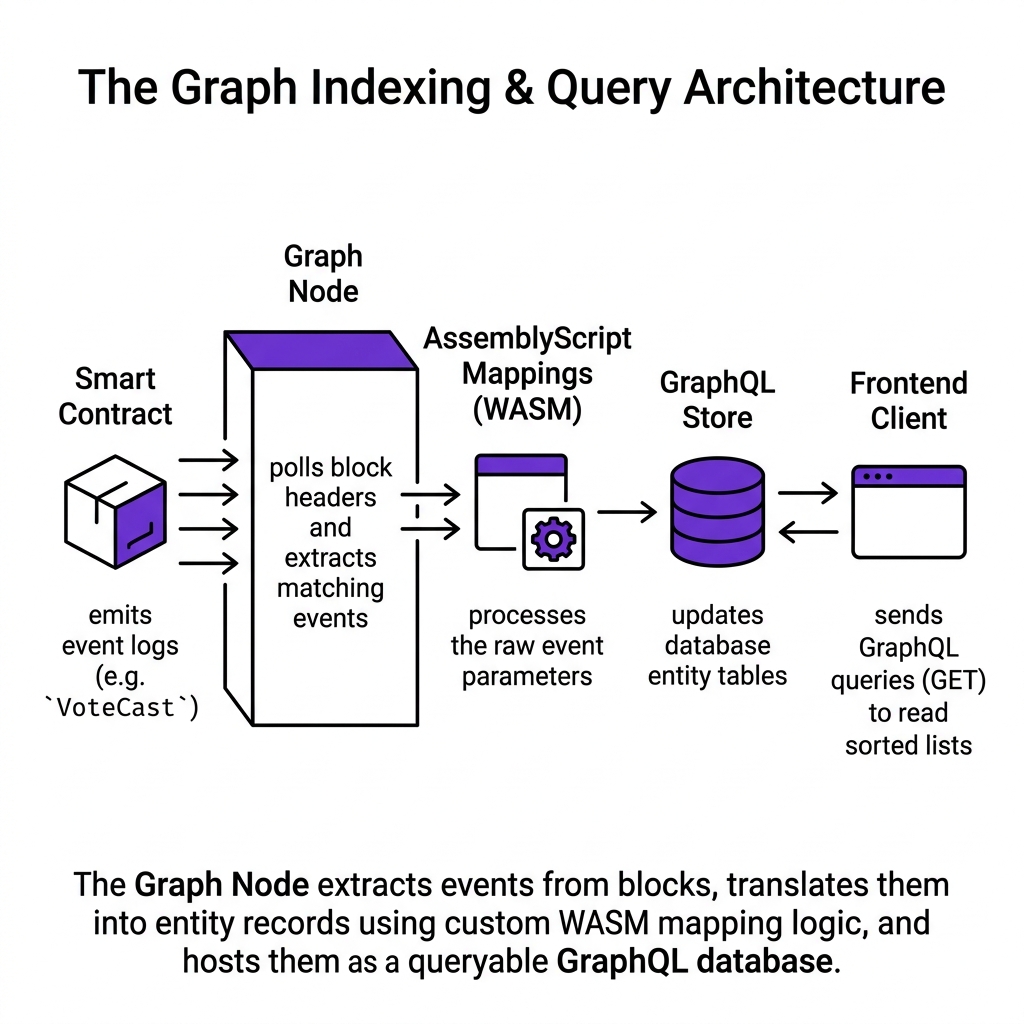
2. What a Subgraph Actually Is
A subgraph is three files that you write, which tell The Graph how to process your contract's events:
File 1: subgraph.yaml — the manifest
File 2: schema.graphql — the data model
File 3: mapping.ts — the event handler (AssemblyScript)
That's the entire subgraph. You write three files. Deploy them. The Graph does the rest — indexing all historical events and watching for new ones.
3. Technical Explanation: The Indexing Process
When you deploy a subgraph, The Graph indexer:
-
Historical sync: Fetches all blocks from the contract's
startBlockto the current block. For every block containing your contract's events, it runs your handler functions. This is the "initial sync" — can take minutes to hours depending on history depth. -
Real-time indexing: After historical sync, the indexer subscribes to new blocks. Every new block is checked for relevant events. Handlers run near-instantly (~1-2 seconds after block finality).
-
Entity storage: Handler functions use a CRUD API (
Entity.load(),entity.save()) to write to The Graph's PostgreSQL database. These are your data entities. -
Query serving: The GraphQL API is served from the PostgreSQL database, not from the blockchain. This is why queries are fast — they're standard SQL joins under the hood.
The Graph's hosted service (Subgraph Studio) is free for development. Production usage requires allocating GRT tokens (The Graph's native token) to attract indexers to process your subgraph. For most projects, the hosted service is sufficient. High-traffic production subgraphs should plan for indexer economics.
Look at ChainElect's contract events: VoterRegistered, CandidateAdded, Voted, VotingStarted, VotingEnded, VoterReset. For each event, think about what entity it would create or update in a subgraph schema. Which events would need to update the same entity (hint: Voted and VoterReset both affect voter state)? Sketch a schema.graphql with at least 3 entity types that would support the ChainElect admin dashboard's data needs.
Was this lesson helpful?
Let us know what you think of this specification. (submitting anonymously)