
What goes on-chain vs off-chain
Proofs vs data. Gas optimization boundaries.
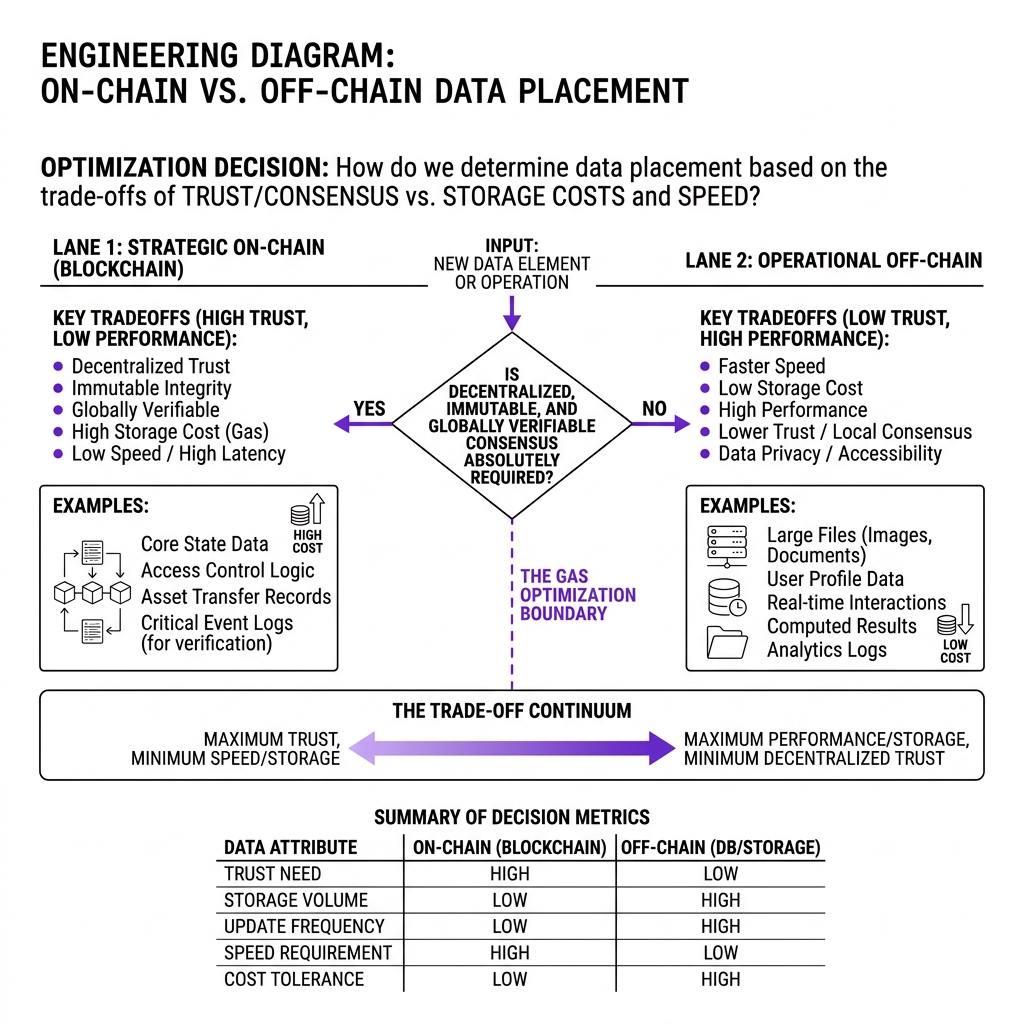
There is exactly one question that determines where a piece of data lives in a Web3 system:
Does this data need to be verified by people who don't trust each other?
If yes: on-chain.
If no: off-chain.
That's it. Everything else — cost, speed, queryability — flows from that single constraint.
1. Why the Boundary Exists
On-chain storage is the most expensive storage medium ever invented for general use.
Here are real numbers from Ethereum mainnet:
Databases store a 50 MB PDF for fractions of a cent. IPFS stores it for free (pinning aside).
On-chain storage is not competing with databases on price. It is offering something databases cannot: consensus without a trusted intermediary.
That premium is only worth paying for data that genuinely requires it.
2. The Decision Framework
Walk every data field through this decision tree:
3. ProofChain: Walking Every Field
ProofChain is a document proof-of-existence system. A user uploads a contract PDF and gets proof it existed unmodified at a specific time, owned by a specific wallet.
Let's walk every data field:
The ProofChain contract stores exactly 3 fields per proof:
Everything else — the filename, IPFS link, description, owner display name — lives in Firebase. The frontend reads Firebase for display, and reads the contract to verify integrity.
4. The Mistake: Storing the IPFS CID On-Chain
When I first designed ProofChain, I stored the IPFS CID on-chain alongside the hash. My reasoning: "the CID proves where the file is." This was wrong for two reasons. First, the CID is derivable from the hash — it's redundant data. Second, IPFS CIDs can be unpinned and disappear. Storing a pointer to potentially-missing data on a permanent ledger creates false confidence. The hash is the proof. The CID is a convenience link. One belongs on-chain. One belongs in Firebase.
5. The Gas Packing Rule
When you do put data on-chain, pack it into storage slots efficiently.
The EVM stores state in 32-byte slots. If your struct fields don't fill complete slots, you waste money.
Wasteful layout:
Packed layout:
The rule: order your struct fields from largest to smallest, group address + small uints together.
6. The Off-Chain Storage Decision
Once a field is confirmed off-chain, you still need to choose where:
ProofChain's routing:
- IPFS: stores the actual PDF file
- Firebase: stores filename, CID, owner display name, description
- The Graph: indexes
ProofLoggedevents for wallet → proof history queries - On-chain: only the 3-field struct above
"But what if Firebase goes down? The proof is lost." No. The cryptographic proof is the hash on-chain. Firebase going down means the frontend can't display the filename. The tamper-evidence is unaffected. Design your system so that the off-chain layer failing degrades UX gracefully, but never compromises the core trust primitive.
You are designing a decentralized freelance marketplace. A client posts a job. A freelancer delivers work. Payment is released on delivery approval. For each of the following fields, apply the decision framework and assign it to the correct storage layer: (1) agreed payment amount, (2) freelancer's portfolio URL, (3) client's approval signature, (4) project description text, (5) dispute resolution vote, (6) freelancer's wallet address, (7) delivery timestamp.
Was this lesson helpful?
Let us know what you think of this specification. (submitting anonymously)